Den gode database for CV
- Ali Günel (NNIT) (Unlicensed)
- Kasper Birkelund Larsen (Unlicensed)
Dette dokument beskriver generelle retningslinjer for modellering af CV tabeller.
Navngivning af databasetabeller og kolonner
Der anvendes engelske navne, med CamelCase. Tabeller bør placeres i Schema som følger opdelingen i Byggeblokke/domæner. Se også under History tabeller, hvor der tilføjes History til navnet.
Navngivningen af kolonner bør følge domænemodellens elementer og attributter (fra C# koden). Navnene oversættes til engelsk og CamelCase anvendes.
Fact- og historik-tabeller (Revisionslog) (TBD)
Generelt skal alle ændringer til data som indgår i sagsbehandling gemmes, så det er muligt at finde tilbage til tidligere versioner af data. Dette for alle tabeller der indeholder sagsrelaterede data. Systemtabeller og andre styringstabeller kan typisk undvære historiktabeller så længe registreringer logges. Se mere om logning:
Der opereres med to typer tabeller:
- Fact-tabeller,
- History-tabeller, navngives som <Onlinetabelnavn> + History
Til alle Fact-tabeller oprettes en History tabel, hvori alle inserts, update og delete operationer registreres, samtidig med at den resulterende record ligger tilbage i Fact-tabellen. Ved sletning fjernes recorden fra Fact-tabellen. Fact-tabellen indeholder på den måde alt der endte med at blive til noget. Se mere om historik her: Den gode historik
Kolonner i Fact-tabellen
Tabellen indeholder følgende ekstra data udover de data som findes i online tabellen:
| Kolonnenavn | Type | Detaljer | Forekomst | Beskrivelse |
|---|---|---|---|---|
| Id | INT (Primary key, Identity) | 1 | Id er primary nøgle til Entitet. | |
| ExternalIdentifier | GUID | 0..1 | Eksternt Identifier til Entitiet. Må udstilles til eksterne. Denne kolonne kan udelades hvis elementet ikke selvstændigt refereres af eksterne. | |
| Alle kolonner fra entitet | EntitetType | 1 | ||
| EntitetId | INT (ForeingKey) | 1 | EntitetId er fremmed nøgle til relation tabel. |
Kolonner i History-tabellen
Tabellen indeholder følgende ekstra data udover de data som findes i online tabellen:
| Kolonnenavn | Type | Detaljer | Forekomst | Beskrivelse |
|---|---|---|---|---|
| Id | INT(Primary key) | 1 | Entitet er entitetsnavnet | |
| Alle kolonner fra entitet | EntitetType | 1 | ||
| Metadata-felter | 1 | Se liste af metadata-felter nedenfor | ||
| Operation | tinyint | 1 | 1=Created, 2=Update, 3=Delete, ved Delete sættes LastUpdatedByxxx felterne i den originale struktur. |
Read operationer logges ikke i revisionsloggen, men logges i stedet i systemloggen i logfil, se:
Metadata-felter der bør være i alle tabeller
| Kolonnenavn | Type | Detaljer | Forekomst | Beskrivelse |
|---|---|---|---|---|
| EntitetIdentifier | GUID (samme key som i online tabel) | 1 | Entitet er entitetsnavnet | |
| ActiveOrganisationTypeIdentifier | OrganisationTypeIdentifierType Base: Byte | 1 | Den myndighed som der er registreret på vegne af (v/ AA: som brugeren har impersonated). Det er den ansvarlige myndighed | |
| ActiveOrganisationCode | String | Length: 1-20 | 1 | Koden som identificerer organisationen. Det kan være Jobcenternummer, et CVR nummer, en a-kassekode eller en kommunekode. Det er den ansvarlige myndighed |
| UserFullName | UserFullNameType Base: String | Length: 1-140 | 1 | Brugers fulde navn, ved systemkald angives systemets og jobbets navn her. |
| RequestUserTypeIdentifier | Base: Byte | 1 | Kodeliste med brugertyperne:
| |
| UserIdentifier | UserIdentifierType Base: String | Length: 1-255 | 1 | Unik identifikation af brugeren, f.eks. en GUID, et medarbejder ID, system ID, bruger ID, certifikat ID, cpr-nummer, email (hvis den er unik) o.l. Afhængigt af RequestUserTypeIdentifier udfyldes feltet med:
|
| UserEmail | EmailAddressIdentifierType String (E-mail) | Length: 2-256 Pattern: ([^>\(\)\[\]\\,;:@\s]{0,191}@[^>\(\)\[\]\\,;:@\s]{1,64}) | 0-1 | Brugerens e-mail adresse |
UserOrganisationTypeIdentifier | OrganisationTypeIdentifierType Base: Byte | 1 | Kodeliste som identificerer typen af organisationen som brugeren hører til. Dette er en kodeliste, dog som integer af historiske årsager. | |
| UserOrganisationCode | String | Length: 1-20 | 1 | Koden som identificerer organisationen som brugeren hører til. Det kan være et Jobcenternummer, CVR nummer, en a-kassekode eller en kommunekode. |
| CreatedDateTime | Erstattes af DFDGRegistrationDateTime | |||
| UpdatedDateTime | Erstattes af DFDGRegistrationDateTime | |||
| RegistrationDateTime | Udgår! (Eksternt registreringstidspunkt) | |||
| DFDGRegistrationDateTime | DateTime | 1 | Registreringstidspunkt i DFDG | |
| CorrectionComment | String | Length: 0-1500 | 0-1 |
Felterne med bruger og organisation stammer fra sikkerhedsmodellen for DFDG, se STARs sikkerhedsmodel.
Ændringer pr primo 2019 med rødt og grønt
Ved konvertering fra CreatedDateTime+UpdatedDateTime til DFDGRegistrationDateTime bruges CreatedDateTime som datagrundlag for DFDGRegistrationDateTime for create metoder og UpdatedDateTime for update metoder.
ID'er (nøgler og fremmednøgler)
Generelt anvendes INT'er som ID og primary nøgle i tabeller. Interne Id'er må ikke udstiller via api. I nøgle situationer skal overvejes om tabelen skal have extern Id som Guid som kan udstilles.
Tabeller der indeholder persondata (CPR-nummer eller PersonId)
For tabeller der indeholder persondata, arbejdes mod at anvende PersonId på alle tabeller fremfor CPR-nummer (PersonCivilRegistrationIdentifier).
Person tabel , der representerer borger og kan mappes til CPR-Id via en mapningstabel. Person.Id er unik til CPR-nummer og må ikke ændres. Der dannes ny Person.Id til ny CPR-nummer.

Index'es
Lav et effektivt clustered index, f.eks. ved at inkludere CPR-nummer/PersonId i indexet.
Lav altid et clustered index. Tabeller uden clustered index kaldes Heaps.
De ligger spredt over disken, hvorend sqlserveren kan finde et ledigt hul og er ikke gemt i nogen som helst orden.
Det giver hurtige inserts, da SQL Server bare kan smide data hvor det skal være, men langsom select, update og delete
Kun i sjældne tilfælde er det hurtigere at have en heap end ikke. Det kunne f.eks. være hvis man har en staging tabel hvor data indsættes og bagefter trækkes alle rækker ud igen, men ellers ikke
Dokumentation
Alle tabeller og kolonner dokumenteres via MigrationBuilder.
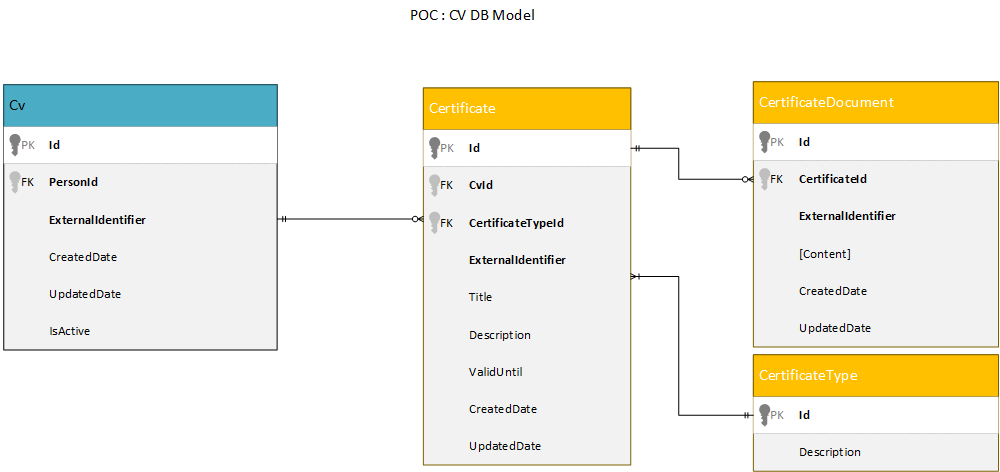
POC til CV Tabeller
Teknologi og udviklernoter
Versionsstyring
Modellen for databasen og de enkelte tabeller skal versionsstyres på lige fod med koden. Dette kan på Microsoft SQL og .NET platformen med fordel foregå ved et af følgende tekniske tiltag:
- Scripting, hvor scripts versionsstyres
- Entity Framework Migrations, hvor strukturen ligger i koden med mulighed for at opgradere